3 Units of Code
3.1 Organization Matters
We often develop units of code in a bottom-up fashion with some top-down planning. There is nothing surprising about this strategy because we build code atop of existing libraries, which takes some experimentation, which in turn is done in the REPL. We also want testable code quickly, meaning we tend to write down those pieces of code first for which we can develop and run tests. Readers don’t wish to follow our development, however; they wish to understand what the code computes without necessarily understanding all the details.
So, please take the time to present each unit of code in a top-down manner. This starts with the implementation part of a module. Put the important functions close to the top, right below any code and comments as to what kind of data you use. The rule also applies to classes, where you want to expose public methods before you tackle private methods. And the rule applies to units, too.
3.2 Size Matters
Keep units of code small. Keep modules, classes, functions and methods small.
A module of 10,000 lines of code is too large. A module of 1,000 lines is tolerable. A module of 500 lines of code has the right size.
One module should usually contain a class and its auxiliary functions, which in turn determines the length of a good-sized class.
And a function/method/syntax-case of roughly 66 lines is usually acceptable. The 66 is based on the length of a screen with small font. It really means "a screen length." Yes, there are exceptions where functions are more than 1,000 lines long and extremely readable. Nesting levels and nested loops may look fine to you when you write code, but readers will not appreciate it keeping implicit and tangled dependencies in their mind. It really helps the reader to separate functions (with what you may call manual lambda lifting) into a reasonably flat organization of units that fit on a (laptop) screen and explicit dependencies.
For many years we had a limited syntax transformation language that forced people to create huge functions. This is no longer the case, so we should try to stick to the rule whenever possible.
If a unit of code looks incomprehensible, it is probably too large. Break it up. To bring across what the pieces compute, implement or serve, use meaningful names; see Names. If you can’t come up with a good name for such pieces, you are probably looking at the wrong kind of division; consider alternatives.
3.3 Modules and their Interfaces
Equip a module with a short purpose statement.
|
|
Prefer specific export specifications over (provide (all-defined-out)).
A test suite section—
3.3.1 Require
With require specifications at the top of the implementation section, you let every reader know what is needed to understand the module.
3.3.2 Provide
A module’s interface describes the services it provides; its body implements these services. Others have to read the interface if the external documentation doesn’t suffice:
Place the interface at the top of the module.
|
|
As you can see from this comparison, an interface shouldn’t just provide a list of names. Each identifier should come with a purpose statement. Type-like explanations of data may also show up in a provide specification so that readers understand what kind of data your public functions work on.
While a one-line purpose statement for a function is usually enough, syntax should come with a description of the grammar clause it introduces and its meaning.
|
Use provide with contract-out for module interfaces. Contracts often provide the right level of specification for first-time readers.
At a minimum, you should use type-like contracts, i.e., predicates that check for the constructor of data. They cost almost nothing, especially because exported functions tend to check such constraints internally anyway and contracts tend to render such checks superfluous.
If you discover that contracts create a performance bottleneck, please report the problem to the Racket developer mailing list.
3.3.3 Uniformity of Interface
Pick a rule for consistently naming your functions, classes, and methods. Stick to it. For example, you may wish to prefix all exported names with the name of the data type that they deal with, say syntax-local.
Pick a rule for consistently naming and ordering the parameters of your functions and methods. Stick to it. For example, if your module implements an abstract data type (ADT), all functions on the ADT should consume the ADT-argument first or last.
Finally pick the same name for all function/method arguments in a module
that refer to the same kind of data—
3.3.4 Sections and Sub-modules
Finally, a module consists of sections. It is good practice to separate the sections with comment lines. You may want to write down purpose statements for sections so that readers can easily understand which part of a module implements which service. Alternatively, consider using the large letter chapter headings in DrRacket to label the sections of a module.
With rackunit, test suites can be defined within the module using define/provide-test-suite. If you do so, locate the test section at the end of the module and require the necessary pieces for testing specifically for the test suites.
As of version 5.3, Racket supports sub-modules. Use sub-modules to formulate sections, especially test sections. With sub-modules it is now possible to break up sections into distinct parts (labeled with the same name) and leave it to the language to stitch pieces together.
|
$ raco test fahrenheit.rkt |
3.4 Classes & Units
(I will write something here sooner or later.)
3.5 Functions & Methods
If your function or method consumes more than two parameters, consider keyword arguments so that call sites can easily be understood. In addition, keyword arguments also “thin” out calls because function calls don’t need to refer to default values of arguments that are considered optional.
Similarly, if your function or method consumes two (or more) optional parameters, keyword arguments are a must.
Write a purpose statement for your function. If you can, add an informal type and/or contract statement.
3.6 Contracts
A contract establishes a boundary between a service provider and a service consumer aka server and client. Due to historical reasons, we tend to refer to this boundary as a module boundary, but the use of "module" in this phrase does not only refer to file-based or physical Racket modules. Clearly, contract boundary is better than module boundary because it separates the two concepts.
When you use provide with contract-out at the module level, the boundary of the physical module and the contract boundary coincide.
module, as in submodule.
Using the first one, define/contract, is like using define except that it is also possible to add a contract between the header of the definition and its body. The following code display shows a file that erects three internal contract boundaries: two for plain constants and one for a function.
|
- Add the following line to the bottom of the file:
(celsius->fahrenheit -300)
Save to file and observe how the contract system blames this line and what the blame report tells you. - Replace the body of the celsius->fahrenheit function with
(sqrt c)
Once again, run the program and study the contract exceptions, in particular observe which party gets blamed. Change the right-hand side of AbsoluteC to 0.0-273.15i, i.e., a complex number. This time a different contract party gets blamed.
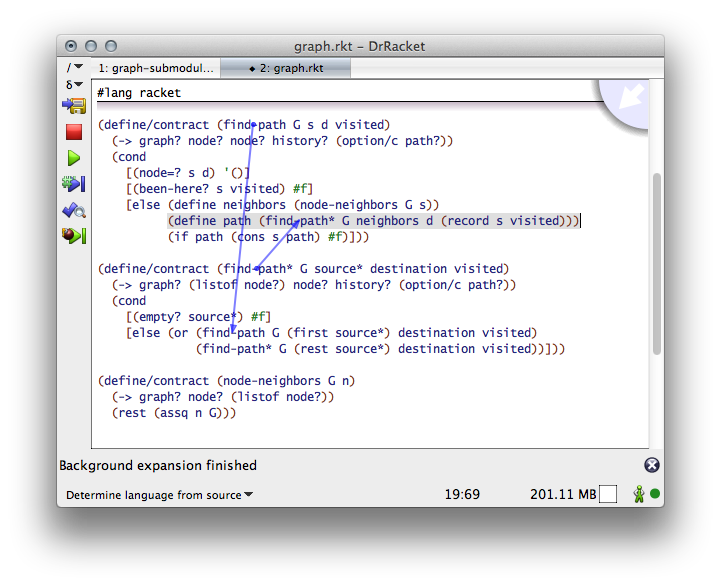
In contrast, submodules act exactly like plain modules when it comes to contract boundaries. Like define/contract, a submodule establishes a contract boundary between itself and the rest of the module. Any value flow between a client module and the submodule is governed by contracts. Any value flow within the submodule is free of any constraints.
|
Since modules and submodules cannot refer to each other in a mutual recursive fashion, submodule contract boundaries cannot enforce constraints on mutually recursive functions. It would thus be impossible to distribute the find-path and find-path* functions from the preceding code display into two distinct submodules.